The Eclipse debugger in action.
At some point, one of your programs is likely to do something you did not expect it to do, and in such a scenario, you are going to have to debug your code. Fortunately, whether you are using the command line Python interpreter, the IDLE interface, or a third-party IDE, there are multiple options for debugging.
Debugging Options
One option is to rely on the error messages Python provides. If you already know Python, and especially if you understand your own code, this is often enough: you just read the error message and go and fix the tagged line and file. It may not always be a good option, however, for larger programs you did not write.
Another possibility, and probably the main way that Python programmers use for debugging their code is to insert print statements and run the program again. Because Python runs immediately after changes, this is usually the quickest way to get more information than error messages provide. Typically, a display of variable values is enough to provide the information you need.
For larger systems you did not write, and for beginners who want to trace code in more detail, most Python development GUIs have some sort of point-and-click debugging support. IDLE has a debugger as well, but it does not appear to be used very often (possibly because it has no command line, or possibly because adding print statements is usually quicker than setting up an IDLE GUI debugging session. But other IDEs such an Eclipse, NetBeans, Komodo and Wing IDE offer advanced point-and-click debuggers.
Python comes with a source-code debugger named pdb, available as a module in Python’s standard library. In pdb, you type commands to step line by line, display variables, set and clear breakpoints, or continue to a breakpoint or error. It can be launched interactively by importing it, or as a top-level script. Either way, it provides a powerful debugging tool.
To provide a real-world example of debugging to solve a coding problem, I introduced a bug into the binary sort code. The code is provided here; some readers may be able to find the bug just by looking at the code. In any case, when we run the code, we get the following result:
[None, None, 17, 144, 372, 51, 79, 123, 519, 997]
This result is wrong for at least two reasons. First, two list members have been replaced with “None”. Secondly, the list is not sorted. Fortunately, this gives us an opportunity to use our debugging skills. The heapSort function does the following:
- Creates a binary heap.
- While there is at least one item on the heap, delete the top item from the heap. If there is remaining heap data, rebuild the heap, consolidate the heap, and repeat this step.
A cursory review of the code seems to indicate that we correctly deleted the top item and re-inserted it after the heap. The error must be in heapify, rebuildHeap, or consolidateHeap. For starters, I decided to set a breakpoint after heapify is called and check to see if it returns a valid binary heap. If it does, we can be pretty sure the error is in rebuildHeap or consolidateHeap.
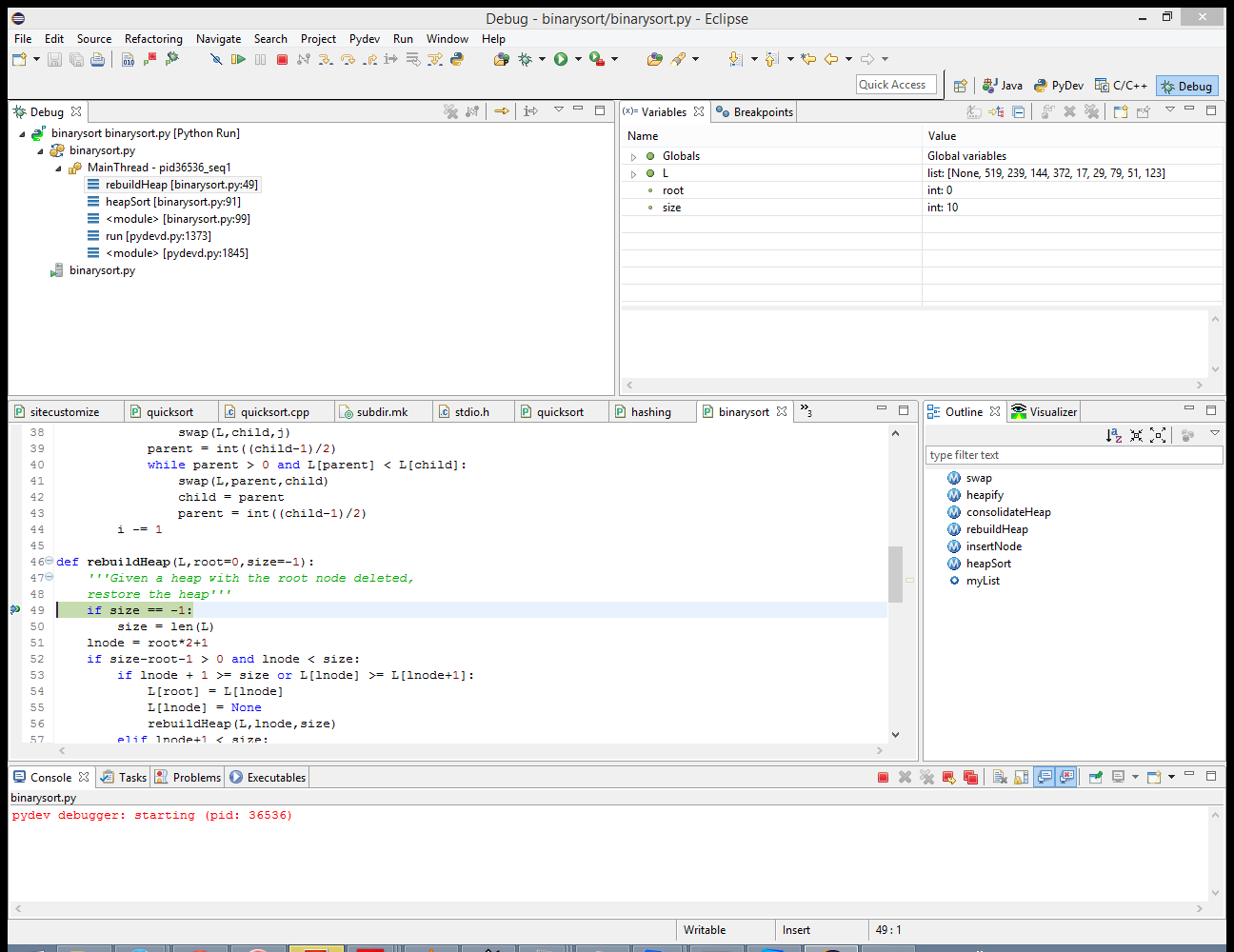
In Eclipse, I set a breakpoint in the second line of heapSort by right mouse-clicking on the left column next to that line of code (the column containing numbers indicating what line of code it is) and selecting “Add Breakpoint). Now I was able to debug the code by pressing “F11”. Eclipse now presents a dialog box asking if I want to switch to the debug perspective. Since I do, I press “Yes” and continue.
In the upper right corner of the Debug perspective, there is a section with two tabs: “Variables” and “Breakpoints”. The “Variables” tab provides us the information about local variables, including the current values stored in L. We can confirm that the list items form a valid binary heap:
997
/ \
519 239
/ \ / \
144 372 17 29
/ \ /
79 51 123
It does not appear that the problem is in heapify, so it must be in either rebuildHeap or consolidateHeap. To find the bug, we will first step through the heapSort function line by line, by pressing F6.
As soon as we press F6 the first time, the variable high shows up on the variable list, since it has now made its first appearance in the code. The same goes for temp, when it makes its first appearance two lines later. The next line deletes the top node, and the change is reflected in the values for L shown on the “Variables” tab. All is well so far.
But after we run rebuildHeap for the first time, it is a different story. Our “heap” looks like this:
519
/ \
None 29
/ \ / \
144 372 17 None
/ \ /
79 51 123
It looks like rebuildHeap has failed us. Nodes marked “None” should not have children. The next step will be to remove the breakpoint from heapSort and put a breakpoint in rebuildHeap. Then we will restart the program. We terminate the program by pressing “CTRL-F2” and then pressing “F11” again.
Once we do this, we can continue debugging and begin stepping through the source code again. Looking at the “Variables” tab, we can see that lnode (left node) is initially set to 1, the correct value for the left node of the root node. The next line checks to see if there is at least one heap item and a left node. There is, so we proceed to the next line. We have to promote either the left node or the right node. We promote the left node if it is greater than the right node or if there is no right node. If so, we assign the left node’s value to the root node, mark the left node as empty, and run rebuildHeap recursively on the left node. When we reach the recursive rebuildHeap call, we will use “F5” to step into the second copy of rebuildHeap.
Once we start stepping into the second rebuildHeap, we can see something is wrong. lnode is now 5, but as the lnode of the lnode of the root, it should be 3. This is because root is equal to 2 when it should be 1. Looking at the first recursive rebuildHeap call in the function, we see that the second parameter is lnode+1 (which calls the function recursively on the right node), when it should be lnode (to call the function recursively on the left node). If we keep stepping through the code, rebuildHeap will perform operations on the wrong nodes and tamper with the integrity of heap data that should be kept intact. Here, it will promote one of the children of the right node, and erase data, as we can see by viewing list L’s values just before the next rebuildHeap call:
[519, None, 29, 144, 372, 17, None, 79, 51, 123]
In other words, it looks this is what accounts for the error in rebuildHeap. We could continue to step through the code, but to save time, let’s change the second rebuildHeap parameter at line 56 to lnode, remove the breakpoint, and see what happens.
Running the program after that modification results in the following output:
[17, 29, 51, 79, 123, 144, 239, 372, 519, 997]
Thus, it seems as if we have isolated and fixed the bug that was causing the error we were seeing earlier. This does not guarantee that our code is bug-free, but if there are other bugs to be found, we can have some confidence that the methods used here can be applied to finding them.
In this example, we used the Eclipse debugger for debugging, but don’t let this discourage you from using whatever tools you want. The Winpdb system, for example, is an open source stand-alone debugger with advanced debugging support and cross-platform GUI and console interfaces. These options become more important as you start writing larger scripts, but at least Python’s debugging support makes the process of finding errors a lot easier than they might be otherwise.
External Links:
The official Eclipse web site – An excellent IDE with good debugging capabilities


Recent Comments