![]() In the previous article, we covered creating and accessing databases with Sqlite. In this article, we continue our look at the Python database APIs.
In the previous article, we covered creating and accessing databases with Sqlite. In this article, we continue our look at the Python database APIs.
You must download a separate DB API module for each database you need to access. Modules exist for most major databases with the exception of Microsoft’s SQL Server. You can access SQL Server using an ODBC (Open Database Connectivity) module, though. In fact, the mxODBC module can communicate with most databases using ODBC on Windows or an OBDC bridge on UNIX or Linux.
A complete listing of databases is available at the official Python wiki. You just need to download the modules you need, and follow the instructions that come with the modules to install them. You may need a C compiler and build environment to install some of the database modules. If you do, it will be described in the module’s own documentation. For some databases, such as oracle, you can choose among a number of slightly different modules.
Python Database Programming: Creating a Connection Object
A Connection object provides the means to communicate from your script to a database program. Note the major assumption here that the database is running in a separate process (or processes). The Python database modules connect to the database. They do not include the database application itself.
Each database module needs to provide a connect function that returns a connection object. The parameters that are passed to connect vary by the module and what is required to communicate with the database.
| Parameter | Usage |
|---|---|
| Dsn | Data source name. This usually includes the name of your database and the server where it’s running. |
| Host | Host, or network system name, on which the database runs. |
| Database | Name of the database. |
| User | User name for connecting to the database. |
| Password | Password for the given user name. |
The above table summarizes some of the more common parameters. For example, here’s a typical connect statement:
conn = dbmodule.connect(dsn='localhost:MYDATABASE', user='chris', password='agenda')
With a Connection object, you can work with transactions, close the connection, and get a cursor.
A cursor is a Python object that enables you to work with the database. In database terms, the cursor is positioned at a particular location within a table or tables in the database, much like the cursor on your screen when you’re editing a document, which is positioned at a pixel location.
To get a cursor, you need to call the cursor method on the connection object:
cursor = conn.cursor()
Once you have a cursor, you can perform operations on the database, such as inserting records.
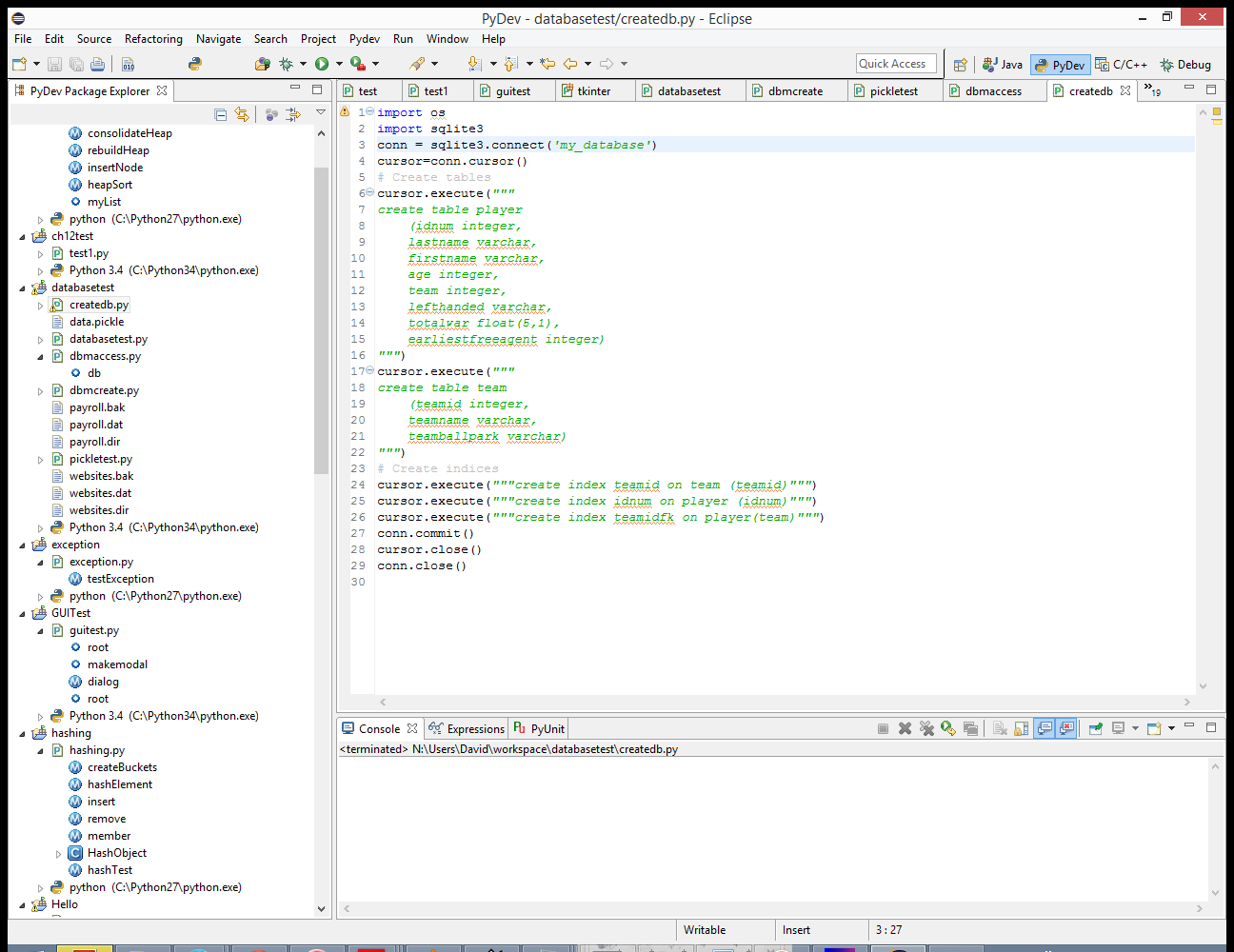
import os
import sqlite3
conn = sqlite3.connect('my_database')
cursor=conn.cursor()
# Create players
cursor.execute("""
insert into player(idnum,lastname,firstname,age,team,lefthanded,totalwar,earliestfreeagent)
values(100,"d'Arnaud",'Travis',26,18,'No',0.0,2020)""")
cursor.execute("""
insert into player(idnum,lastname,firstname,age,team,lefthanded,totalwar,earliestfreeagent)
values(101,'Duda','Lucas',29,18,'Yes',2.9,2018)""")
cursor.execute("""
insert into player(idnum,lastname,firstname,age,team,lefthanded,totalwar,earliestfreeagent)
values(102,'Harper','Bryce',22,20,'Yes',9.6,2019)""")
# Create teams
cursor.execute("""
insert into team(teamid,teamname,teamballpark)
values(18,'New York Mets','Citi Field')""")
cursor.execute("""
insert into team(teamid,teamname,teamballpark)
values(20,'Washington Nationals','Nationals Park')""")
conn.commit()
cursor.close()
conn.close()
The first few lines of the script set up the database connection and create a cursor object:
import os
import sqlite3
conn = sqlite3.connect('my_database')
cursor=conn.cursor()
Note how we connect to an Sqlite database. To conect to a different database, replace this with your database-specific module, and modify the call to use the connect function from that database module, as needed.
The next several lines execute a number of SQL statements to insert rows into the two tables set up earlier: player and team. The execute method on the cursor object executes the SQL statement:
cursor.execute("""
insert into player(idnum,lastname,firstname,age,team,lefthanded,totalwar,earliestfreeagent)
values(100,"d'Arnaud",'Travis',26,18,'No',0.0,2020)""")
This example uses a triple-quoted string to cross a number of lines as needed. You will find that SQL commands, especially those embedded within Python scripts, are easier to understand if you can format the commands over a number of lines. This becomes helpful with more complex queries. Also, note that we used double quotes around the last name in this example (“d’Arnaud”) so we could include an apostrophe in the name (if we used single quotes, the apostrophe, identical to a single quote mark, would have denoted the end of the string).
To save your changes to the database, you must commit the transaction:
conn.commit()
Note that this method is called on the connection, not the cursor.
When you are done with the script, close the cursor and then the connection to free up resources. In short scripts like this, it may not seem important, but it helps the database program free its resources, as well as your Python script:
cursor.close() conn.close()
You now have a small amount of sample data to work with while using other parts of the DB API.
External Links:
Database Programming at wiki.python.org

Recent Comments